8. Multipipelined (superscalar) processors
Ideal case theoretical efficiency of pipeline = 1 CPI
Processor cannot execute an instruction in a fraction of a cycle but may execute multiple instructions in a single cycle
must have more than one execution pipeline
Multi-pipelines or Superscalars
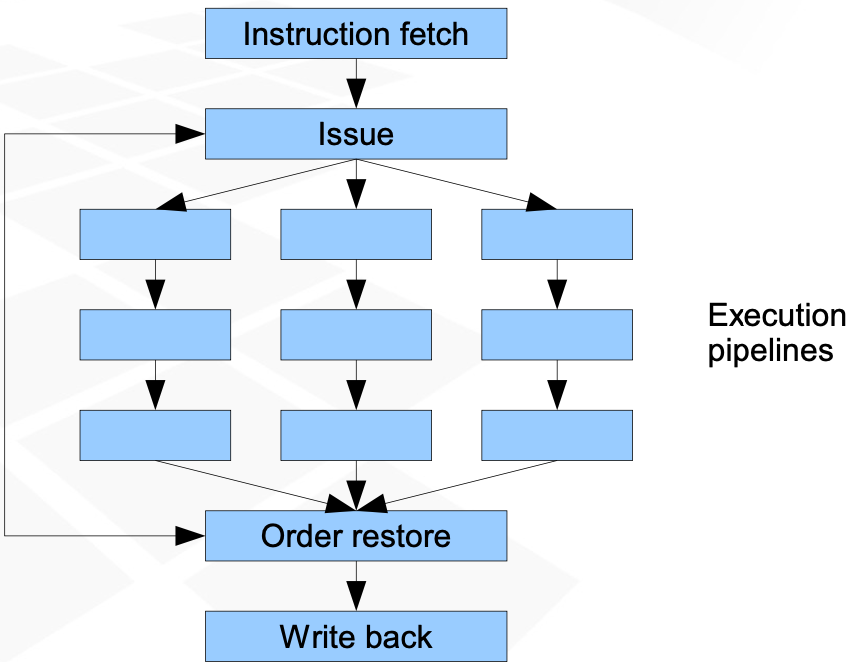
Structure and operation
Initial stages fetch and decode several instructions simultaneously
The issue (scheduler) stage directs instructions to individual pipelines for execution
each pipeline may start one instruction in every cycle
not always possible to start a new instruction every cycle in every pipeline
Execution pipelines execute single instructions
Reorder stage schedules instructions for completion and modifies software-visible PC (not present in simple versions)
WB irreversibly modifies computer's software context (registers and memory)
Classes of superscalars
Pseudosuperscalar
Cannot decide by itself if instructions can be issued simultaneously - must be decided by the programmer or compiler
this information is encoded explicitly in the instruction image
Both pipelines are executed at the same time
if one must stall, both do
In-order execution superscalar
The processor decides if instructions can be issued simultaneously
Pipelines may be identical, similar or different
one may execute all instructions, the other only simple
Instruction issue
Instruction groups - after group of (2-4) instructions is fetches, the instructions from the group are issued simultaneously or sequentially. Then the next group issue starts on the next cycle
Instruction window - in every cycle the issue stage has as many instructions available for issue as there are pipelines in the processor
In-order issue, out-of-order completion superscalar
Instructions are fetched and decoded in groups
Scheduler stage starts instructions in their program order
Stalling the pipeline doesn't influence other pipelines
better efficiency
Problem - change of instruction order may introduce new synchronization problems
Out-of-order execution superscalar
Decoded instruction are stored in scheduler stage
Instructions are scheduled for execution when their arguments are ready
Two scheduling strategies:
- Central instruction buffer from which instruction are issued
- Buffers as first stages of individual exec pipelines
Operation
At any time, the processor must have a valid content of PC
After passing exec pipelines, instruction wait for the other ones at RETIRE stage
Instructions do not permanently modify the processor context and memory until it is retired
Synchronization
Consider the sequence
addu $4, $3, $2
addu $2, $5, $6
What value of $2 will be fetched by the first instruction?
This is called Write-After-Read hazard
Consider the sequence
addu $4, $3, $2
addu $4, $8, $9
addu $2, $5, $4
Which value of $4 will be read by the third instruction?
This is called Write-After-Write hazard
WAR and WAR hazards
The hazards do not result from simple instruction dependency
in case of WAR, the dependency would be present if the instruction order was reversed
this is called false dependency or antidependency
Removing WAR and WAW hazards require understanding their true origin
Sources of WAR and WAW hazards
The hazards originate from reusing the same variables to store different values at different stages of program execution
Caused by:
- limited number of registers in processor
- Simple and clear program text - small number of variables
- Loop structures - value of variable changing on every pass
Solution - increase the number of registers, preferably to infinity
Removing WAR and WAW hazards
Implement significantly more registers than required for a programming model
Dynamically assign physical registers to numbers of logical registers contained in instructions - register renaming
Implementation of register renaming
Every instruction dispatch receives a new physical number of destination register
Subsequent instructions specifying the same register as source get the source register number replaces in the same way
The physical register is freed when the next instruction with the same logical destination register is retired
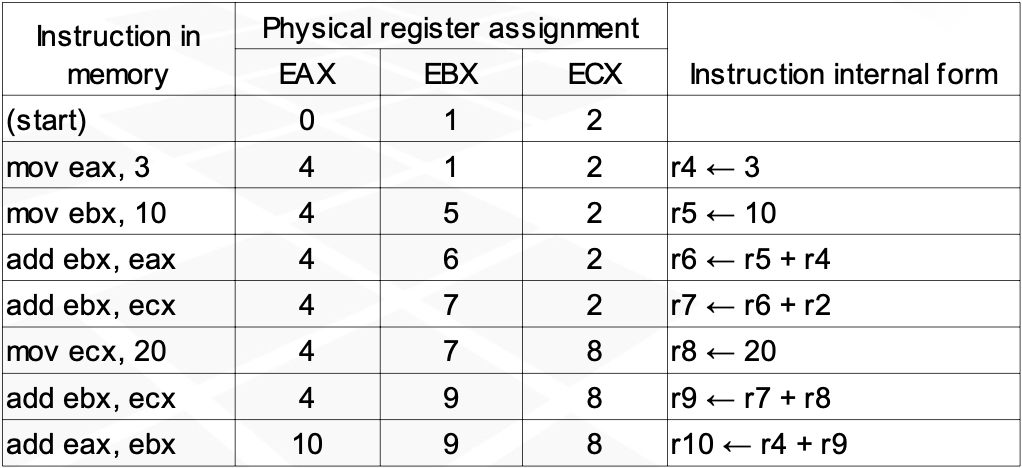
Required number
S - no. of out-of-order stagers
P - no. of programming model registers