Sample questions
Basics
What is a byte?
Byte is a memory unit of 8 bits. It is usually the smallest addressable unit in the computers.
Why should we use binary, not decimal multiples to express the size of primary memory of a computer?
Binary multiples
In case of primary memory (i.e. RAM, Flash Memory), we should specify their sizes in binary decimal, as their size is a multiple of 2, and we use that memory in addresses etc (all multiples of 2).
Producers usually list the memory sizes in decimal multiples, as they are smaller than binary multiples, thus making the sense of a bigger size
100GB = 93.1GiB
Why the memory resources of contemporary computers have hierarchical structure?
Memory hierarchy
The hierarchical structure of memory resources is used to balance speed and cost of data accessibility. At the top, closest to the processing unit are registers and cache, which have the fastest access time, while at the bottom of the hierarchy are slower, external data sources.
Which two memory hierarchy layers are implemented using the same physical device? What device is used to implement them?
RAM and Virtual Memory
Main memory (RAM) and virtual memory are both implemented using DRAM (Dynamic Random-Access Memory)
What is the general rule of object movement between the layers of memory hierarchy?
Object in memory hierarchy
The objects are moved between layers of memory based on their usability by the processing unit. More useful, frequently required objects are moved towards the top of the hierarchy (closer to the processor) which has a quicker access time, while less used objects are moved to the bottom, away from the processor.
How does the connection of instruction memory hierarchy and instruction processor differ from the connection of data memory hierarchy and data processor in Skillicorn's taxonomy?
Skillicorn's taxonomy
In Skillicorn's taxonomy, the IM and IP exchange information about instructions. IP sends an instruction address to the IM, which in returns sends the instruction info - binary image. IP then decodes that info, understanding if there are any needed arguments etc.
DP and DM behave similarly, but they do not exchange instructions info, but data. DP sends a request to DM with the needed data (got from the info from IP), which DM sends to the DP in return.
What is the difference between 'loosely coupled' and 'tightly coupled' multiprocessor in Skillicorn's taxonomy?
Skillicorn's multiprocessor
A multiprocessor in Skillicorn's taxonomy consists of multiple DP-DM pairs, connected to one IP/IM unit. 'Loosely coupled' type has the IP/IM connected to all DPs which in turn are connected to DMs, while 'tightly coupled' type has the instruction unit connected to both DPs and DMs at the same time.
Why the Harvard architecture makes it impossible to write the new program to memory during normal operation of a computer?
Harvard architecture
The Harvard architecture the IM and DM are physically separate, and accessed through two different busses. IP can only read from IM and DP and read form/write to DM. This allows the processor to operate on changing values (DP/DM) but blocks it from making any changes to the instructions (IP can only fetch from IM).
What is the 'von Neumann' bottleneck?
Princeton architecture
The 'von Neumann' bottleneck is related to the Princeton architecture, which combines DM and IM into one memory unit. This allows both DP and IP to fetch and write data on one unified structure, but they cannot use it at the same time. One has to wait for the another in order to fetch/write data from the memory unit.
Why the self-modification of a program is not allowed in Harvard-Princeton architecture?
Harvard-Princeton architecture
Harvard-Princeton architecture disallows a program to make self-modifications to its code/instructions, as its result is is unpredictable.
Data
What is the weight of the most significant bit of an n-bit integer number in unsigned and two's complement notation?
Unsigned and two's complement
In unsigned notation:
In two's complement:
What is the minimum number of bits required for representing a given number in 2's complement encoding?
Two's complement
To represent a number x in two's complement, you need the smallest n such that:
What is the representable range of integers in n-bit unsigned and two's complement notation?
Notation range
Unsigned ->
Two's complement ->
Determine binary pattern of an 8-bit word representing the given number in integer twos'
complement, ones' complement and biased coding with the bias value of 127. (example values: -120, -64, -21, -10, -5, -1)
Conversion
-120 (120 -> 01111000):
2s' complement -> 10001000 (~x+1)
1's complement -> 10000111 (~x)
biased -> -120 + 127 = 7 -> 00000111 (BIAS + x)
-64 (64 -> 01000000):
2s' complement -> 11000000
1's complement -> 10111111
biased -> 00111111
-21 (21 -> 00010101)
2s' complement -> 11101011
1's complement -> 11101010
biased -> 01101110
-10 (10 -> 00001010)
2s' complement -> 11110110
1's complement -> 11110101
biased -> 01110101
Why numeric codes have more than one representation of zero?
Representation of zero
This problem occurs in one's complement and sign-magnitude notations, where the most significant bit sets a sign and the value of later bits can zero it.
For one's complement -> 00...00 == 11...11
For sign-magnitude -> 00...00 == 10..00
Why it isn't necessary to store an integer part of significand in IEEE754 floating/point notation?
Floating point notation
We don't have to store the integer part of the significand, as the only value of the integer part we store is one bit. If it's set to 1, it means the value is normalized (i.e.
Determine binary patterns corresponding to a give number in IEEE754 binary32 floating point format
Decimal to floating conversion
sign|exponent (127 + bin exp)|mantissa
-256
256 -> 100000000
.0 -> 0
100000000.0
move decimal point so it will be normalized
exponent = 127 + bin exp
127 + 8 = 135 -> 10000111
mantissa what's after the dec. point -> 00...00
converted value -> 0 10000111 000000...
-10.125
10 -> 1010
.125 -> 001
10.125 -> 1010.001 =
exp = 127 + 3 = 130 -> 10000010
-10.125 -> 1 10000010 010001000...
-0.75
0.11 ->
-0.75 -> 1 01111110 1000...
15.625
1111.101 ->
15.625 -> 0 10000010 111101000...
How to change the sign of a twos' complement number using only single-argument logic and arithmetic operations?
Sign inversion in 2s' complement
To change the sign of a 2s' complement number we need to first perform a binary negation on the number, then add 1 to it.
A 32-bit word of hexadecimal value 0x12345678 was stored in memory of a little-endian/big-endian computer with 8-bit bytes. Write the address and content of each octet of this word.
Big-Endian, Little-Endian
Let's say that the address pointing to the first octet is p.
For little-endian:
p -> 0x78
p+1 -> 0x56
p+2 -> 0x34
p+3 -> 0x12
For big-endian:
p -> 0x12
p+1 -> 0x34
p+2 -> 0x56
p+3 -> 0x78
What is size-alignment?
Size-alignment
Size-alignment is a method of placing the objects in memory. Physically, the memory is a vector of memory words (which are vectors of bytes). Size-alignment ensures that a single object will be placed in such way, that it is contained within a single memory word. This allows for a quick access to the data, as if the object was split across two memory words, we'd need to make two memory requests to get its data.
Additionally, the starting address of each object should be a multiple of the object's size.
Draw the layout of a given C structure and determine the value of sizeof() operator, assuming natural sizes of data types for a 32-bit processor with 8-bit values.
struct ex {
char a;
short b;
int c;
char d;
double e;
}
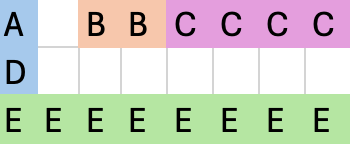
Draw the layout of application's address space in one or more OS'es based on values of addresses of objects from various memory sections displayed by a C program
Memory segments, address space
From the lowest address:
- Text - code, read-only
- Data - above the text segment
initialized data (global and static variables)
uninitialized data (BSS)
- Heap - dynamically allocated memory during program execution.
Starts at low address and grows upwards
- Stack - function calls, local vars, return addresses
Starts at high address and grows downwards
- Memory-mapped segment - shared libraries, mapped files
can be located above the data segment, depending on the system
| Address range | Section |
|---|---|
| 0x0000-0x0040 | Text segment |
| 0x0040-0x0060 | Initialized Data Segment |
| 0x0060-0x0070 | Unitialized Data (BSS) |
| 0x0070-0x01F0 | Heap (dynamically initialized) |
| 0x01F0-0x0200 | Memory-mapped segment |
| 0x0200-0x0300 | Stack |
| Based on the map from the previous question, estimate the possible limits of stack and heap sizes imposed by a given operating system. |
The stack size could theoretically grow to infinity, so the OS sets a stack size limit to prevent stack overflow.
On Linux, the stack size limit is 8MB, while on Windows it varies from 1MB to 4MB
Available heap space should be greater one of stack, as it is enclosed from both sides. It is effectively limited by the amount of virtual memory available on the system.
On 32-bit system, virtual memory is usually 4BG, the OS's split it into two 2GB spaces - one for user-applications, one for kernel.
Application programming model
What does the PC register point to during instruction execution (after fetch is completed)?
PC incrementation
The PC points to the next instruction that will be executed.
Describe the order of actions while using PUSH and POP instruction, assuming 'full descending' stack implementation
PUSH/POP, stack implementation
In full descending stack, the stack grows downward (towards lower memory addresses) and the SP points to the last used (occupied) position in the stack.
PUSH instruction:
- decrement the SP -> move to the next empty location in memory
- store data at the SP location
POP instruction:
- read data from location pointed to by SP
- increment the SP
Describe the order of actions while executing PUSH and POP instruction, assuming “empty ascending” stack implementation.
PUSH/POP, stack implementation
In the empty ascending stack implementation, stack grows upwards (towards higher memory addresses) and points to the first empty position in the stack.
PUSH instruction:
- store the data
- increment the SP
POP instruction:
- decrement the SP
- read the data
Describe the operation of a CALL instruction.
CALL instruction
The CALL instruction is used to transfer execution to a subroutine and ensure that the program can return to the correct location after the subroutine finishes.
Operation:
- push the Return Address onto the stack
- transfer control to the subroutine - update PC to the address of the subroutine
The pushed Return Address can be retrieved by RETURN instruction
Describe the difference between extension of signed and unsigned integers to longer formats.
Format extension
In case of an unsigned integer, the extension to a longer format is very simple, as it requires filling higher-order bits with 0's. This operation is called zero-extension
170 -> 10101010 -> 0000000010101010
In case of signed integers, the operation depends on the used signed representation of the value. In most cases, the 2's complement is used, in which the extension requires filling higher-order bits with the value of the sign bit. This operation is called sign-extension
-22 -> 11101010 -> 1111111111101010
What assembly/machine instructions are used by the compiler to implement division of unsigned and signed numbers by powers of 2 of unsigned and 2’s complement signed numbers?
Diving by powers of 2
For unsigned numbers, a logical right shifting is the best way to divide by powers of 2. If we divide by
For signed numbers, the arithmetic right shift is used. It replicates the sign bit to fill the higher-order bits, ensuring the result remains correct for negative numbers
Determine the decimal value of the result of performing on a given 8-bit two's complement number (-66, -12, 130) (a) left logical, (b) right logical, (c) right arithmetic shift by one bit.
-66 -> 10111110:
a) 01111100 -> 124
b) 01011111 -> 95
c) 11011111 -> -33
-12 -> 11110100:
a) 11101000 -> 230
b) 01111010 -> 122
c) 11111010 -> -6
130 -> 10000010:
a) 00000100 -> 8
b) 01000001 -> 65
c) 11000001 -> -63
What is the difference between x86 SUB (subtract) and CMP (compare)?
Both SUB and CPM instructions are similar in a way, that they both involve subtraction, but their purposes and effects differ significantly.
SUB - performs subtraction between two registers and update the destination register with the result
This operation sets relevant flags in EFLAGS register:
Z - if result is 0
S - if result is negative
OF - is signed overflow occurs
CF - if unsigned borrow occurs
P - even/odd value of LSB of the result
-
CPM - compared two operands by performing a subtraction, but does not store the results. It sets relevant flags in EFLAGS for conditional branching or decision-making
Z - if operands are equal
S - if the result of subtraction is negative ($2 > $1)
OF - if signed overflow occurs
C - if unsigned borrow occurs
P - parity of the LSB of the result
The operands are not modified, only the flags are updated
What is the proper way of (a) setting the register to 0 (b) checking if register contains 0 in x86 architecture assembly programming? Why?
a) proper way of setting the register to 0 is using xor eax, eax instruction. It takes only 1 cycle, while other instructions like mov eax, 0 take more time
b) the best way to compare if register contains 0 is using the
test eax, eax. It performs a bitwise AND of the register with itself but does not modify the register. Sets Z flag in EFLAGS
Why is it more convenient to use the frame pointer rather than stack pointer for stack frame addressing?
Frame pointer is more convenient to use, as it holds the local value of the SP at the beginning of the branch. While SP changes during the code execution, the FP is static for each branch, allowing for indirect access mode without the possibility of it breaking by changing the value of FP mid-procedure.
Draw the layout of a stack frame conforming to x86 C calling convention and determine the addresses of arguments and possible addresses of local variables relative to the frame pointer, given the function's declaration.
(stack grows downwards)
| local var | [EBP - 4]
| Saved EBP | [EBP]
| Return Addr | [EBP + 4]
|Function arg1| [EBP + 8]
|Function arg2| [EBP + 12]
Which addressing modes are necessary for the implementation of a high-level language?
Necessary addressing modes for HHL are:
- Absolute (register direct) mov eax, ebx
- Immediate mov eax, 10
- One version of indirect (usually relative indirect with displacement) mov eax, [ebx + 4]
Determine the names of addressing modes used in a given x86 assembly instruction
mov eax, 10 - immediate
mov eax, ebx - register direct
mov eax, [0x1234] - absolute (direct)
mov eax, [ebx] - register indirect
mov eax, [ebx + 4] - register indirect with displacement
mov eax, [ebx + ecx] - double-register indirect
mov eax, [ebx + ecx * 4] - register indirect indexed
mov eax, [table + ecx * 4] - absolute indexed
What information is recorded by the parity flag?
The parity flag saves the information about whether the number of 1-bits in the LSB of the result is even (1) or odd (0). It was historically used for error detection in communication protocols, right now it's rarely used.
Determine x86 flag values after addition/subtraction/logic operation given the arguments or result value and operation size.
Addition-affected flags - Z, S, OF, C, P, AF
Subtraction - -//-
Logical operations - Z, S, P
-
Addition -> add eax, 0x7f eax = 1, 8-bit operation
01111111 + 00000001 -> 10000000 = -128
Z=0, C=0, S=1, OF=1, PF=0, AF=0
-
Subtraction sub eax, 0x02 eax = 1, 8-bit
00000001 - 00000010 = 11111111 = -1
Z=0, C=1 (source > destination in unsign. arith), S=1, OF=0, PF=1, AF=1
-
Logical and eax, 0xf0
10101011 & 11110000 = 10100000 = 160
Z=0, C=0, S=1, OF=0, P=1, AF=0
What is the orthogonality of instructions versus addressing modes?
Orthogonality of instructions versus addressing modes means that all instructions can be used with all addressing modes.
What is a typical usage of processor registers by HLL compilers in CISC & RISC architectures?
RISC:
- registers are used to pass function arguments (no need to push them onto the stack)
- return values are stored in a specific register
- local variables are primarily stored in register, minimizing memory access. Stack is used in case of insufficient registers
- PC keeps track of the next instrucion to execute
- LR stored the return address for function calls
- Registers may temporarily hold stack data during fast context switches
- Registers hold intermediate results for calculations or temporary values
CISC:
- Arguments are often passed on the stack
- Return values are stored in a specific register
- Local variables are stored on the stack, registers are used sparingly
- EIP is PC
- Base pointer EBP acts as frame pointer
- Flags register EFLAGS stores condition codes for branch instructions
- Stack pointer ESP is used to manage stack calls
- EBP is used to create stack frames for subroutines
- Registers hold intermediate results, but spilling to the stack is more common than in RISC
Why the memory footprint of a program for a RISC processor is usually bigger than the footprint of an equivalent program for a CISC processor?
RISC architecture has a reduced instruction set (hence the name), which contains simple instructions. CISC contains many complex instructions (name), which internally do multiple operations under one instruction. This way, the memory footprint of RISC program is smaller, as it has to make more instruction calls to obtain the same result.
Why is it impossible for a RISC processor to implement an instruction loading a 32-bit immediate constant to a register? What other methods may be used to implement this action?
It is impossible for RISC to load 32-bit immediate constant, as all RISC instructions are 32-bit wide. The li instruction allows for a 12-/16-bit immediate.
To save the value of an 32-bit immediate, we have to 3 options:
- push it onto the stack
- load the constant from memory
- use sequence of instructions
lui t0, 0xABCD ; load upper 20 bits (0xABCD000) into t0
addi t0, t0, 0x1234 ; add lower 12 bites (0x1234)
; result -> t0 = 0xABCD1234
Why the RISC instruction sets usually do not contain register to register copy instruction?
In RISC, the goal is to minimize the number of instructions in the name of simplicity and efficiency. We can achieve the reg-to-reg copy, by using AND or OR instructions
AND a0, t1, x0 OR a0, t1, x0
Explain why most RISC architectures do not have dedicated subroutine return instruction. What instruction is used to return from a procedure in these architectures?
RISC architectures are designed with simplicity and efficiency in mind. There is no need to introduce a subroutine return instruction, as its function can be achieved using already existing instructions.
Return from a subroutine can be handled by jalr instruction.
What is the difference in binary encoding and execution between a relative branch and absolute jump instruction?
The difference between relative branch and absolute jump instruction is in the way they calculate the target address and their execution behaviour.
Relative branch:
- encodes target address as an offset (signed) relative to the current PC. the offset is added to the address of the instruction following the branch instruction, in order to compute the target address.
- This allows code to remain position-independent, allowing code to execute even if loaded from different locations
Absolute jump:
- Encodes full target address directly in the instruction
- Target address can be a memory address or a register containing the address
- CPU loads target address from the instruction and sets the PC to that value
Execution unit
What characteristics of processor's programming model is required to implement the processor as a single-cycle structure.
To create a single-cycle processor, it needs to have:
- fixed instruction length
- simple instruction set (RISC for example)
- sequence of actions is fixed for all instructions
- one memory operation per instruction
- uniform instruction execution time
- Harvard architecture - separate IM and DM
- Limited number of addressing modes
What is the role and operation of ALU during execution of load and store instructions in single-cycle and simple pipelined processors?
During load and store instructions, ALU is used to calculate the address of the memory which will be accessed (to store/load the data).
Write an instruction sequence generating Read-After-Write hazard.
add $4, $3, $2
add $6, $5, $4
Why is it better to remove RAW hazard using bypasses rather than in other ways?
Bypasses are the best way to remove RAW hazard, because they do not create a significant delay in the instruction operation. Other methods of fixing the RAW hazards, like putting nop in between lines creating the hazard, introduce unused clock cycles, which may cause a significant delays in the code execution.
Explain why bypasses cannot resolve load-use penalty without delays.
The load-use hazard is created by trying to use the newly-loaded value in another instruction, while the loading pipeline did not finish the execution yet. The bypasses cannot fix this issue, as they are used to moving data between next pipeline stages (RD -> ALU -> MEM). The used value ($4 needs to pass the MEM stage, in order to be usable by the next instruction), but it doesn't have enough time to get there, even with bypasses.
Bypass fix assume that the ALU creates the value, but in the 'load' instruction, the MEM does that. This requires a 1-cycle wait to make sure that MEM loads the value.
What is the source of branch penalty problem in pipelined processors?
Branch penalty problem in pipelined processors is caused by the fact that before fully acknowledging the branch instruction, the pipeline already loads next instructions (after branch, not the ones of branch). This problem requires the program to unload the loaded instructions, load new instructions (with new program counter) and then execute them. This process introduces delay - branch penalty.
What is a 'delayed branch'?
Delayed branch is one of the solutions to the branch penalty problem. While computing the branch instruction, the next pipeline loads the next instruction. If the instruction does not change the behaviour of the branch, it is executed before the branch instruction, despite being after it in code.
Why delayed branches are not used in superpipelined processors?
Superpipelined processors add stages to the pipeline (6-8 in total). Due to this, the time between instruction fetch and write back (instruction finish) is enlarged. If the branch instruction occurs, the processor won't load a single next instruction (as in simple pipelined processors), but will load multiple (2/3 depending on the amount of pipeline stages). Cleaning this up and fixing would introduce a very big delay, which would make superpipelined processors unreasonably slow.
Outline two methods of a pipelined implementation of CISC processors
First method includes using a decoder, which fetches CISC instructions and converts them into RISC. Then, a RISC pipeline execution unit executes them.
Second method is a direct implementation of CISC instructions, but requires creating complex pipelines capable of executing varying-sized instructions, multiple addressing modes and many instruction formats.
What processor architectures use instruction transcoder and what is its purpose?
Transcoder is a unit which converts CISC instructions into RISC, for a pipeline CISC implementation. It fetches CISC instructions, then converts them into RISC and sends to a RISC execution unit.
Describe the conditions under which a superscalar processor may simultaneously issue two or more instructions to execution pipelines.
The superscalar processor may simultaneously issue multiple instructions to execution pipelines under the following conditions:
- Instruction-Level Parallelism - multiple instructions can be executed independently
- Availability of multiple functional units - ALUs, FPUs, load/store units
- Absence of data hazards - RAW, WAR, WAW hazards
- Control flow independence - instructions can't depend on unresolved branch instructions or other control flow operations
- Pipeline resources availability
In what kind of architectures WAR and WAW hazards may be present?
WAR and WAW hazards may be present in superpipeline, superscalar and out-of-order ! execution architectures.
Write an example of an instruction sequence generating WAR/WAW hazard.
# WAR
Trial test 1
- kB acronym denotes
- 1024 bytes
- 1000 bits
- 1024 bits
- 1000 bytes
- is informal and incorrect
- The addressing mode which cannot be used for specifying the destination argument of an instruction is
- register indirect with PC base (INCORRECT)
- double-register indirect
- immediate
- absolute
In immediate addressing mode, the operand is a constant value directly specified to the instruction. It cannot be used as the destination of an instruction
- 4 main memory sections appearing in application programs are:
- variables
- heap
- procedures
- main program
- constants
- stack
- code
- static data
- stack frame
Variables - data segment (static or dynamic)
Procedures - code segment
Main program - entry point (in text/code segment)
Constant - data segment or code segment
Stack frame - part of the stack