Chapter 9
Strings and Arrays
Most optimisations are performs on efficiently processing strings and arrays. 90% of program eecution is spend on running 10% of the code
This chapter focuses on techniques for string and array processing
String Primitive Instructions
x86 instruction set has five groups of instruction for processing arrays of bytes, words, and doublewords. They are called string primitives, but they are not limited to character arrays
In 32-bit mode, each instruction uses ESI, EDI, or both to address memory. References to the accumulator use AL, AX, or EAX depending on the instruction data size
String primitives execute efficiently because they automatically repeat and modify array indexes
A Direction Flag is a control flag in CPU flags register that determines whether automatically repeated instructions will increment or decrement their target addresses
Primitive Instructions:
| Instruction | Description |
|---|---|
MOVSB, MOVSW, MOVSD |
Move string data - copy from memory ESI to EDI |
CMPSB, CMPSW, CMPSD |
Compare strings - compare contents of two memory locations addresses by ESI and EDI |
SCASB, SCASW, SCASD |
Scan string - compare the accumulator (AL, AX, or EAX) to the contents of memory addressed by EDI |
STOSB, STOSW, STOSD |
Store string data - store the accumulator contents into memory addresses by EDI |
LODSB, LODSW, LODSD |
Load accumulator from string - load memory addressed by ESI into accumulator |
Using a Repeat Prefix
A string primitive instruction processes only a single memory or pair or values. However, by including a repeat prefix, the instruction repeats, using ECX as a counter. The repeat prefix permis to process an entire array using a single instruction. Any one of the following repeat prefixes can be used
| Instruction | Description |
|---|---|
REP |
Repeat while ECX > 0 |
REPZ, REPE |
Repeat while ZF is set and ECX > 0 |
REPNZ, REPNE |
Repeat while ZF is clear and ECX > 0 |
Example - Copy a String
MOVSB moves 10 bytes from str1 into str2. The repeat prefix tests MOVSB instruction. If
Because the DF is first cleared by CLD (Clear Direction Flag) instruction, ESI and EDI are automatically incremented when MOVSB repeats
cld
mov esi, OFFSET str1
mov edi, OFFSET str2
mov ecx, 10
rep movsb
Direction Flag
String primitive instructions increment or decrement ESI and EDI based on the state of the Direction Flag (DF). The DF can be explicitly modified using the following instructions
CLD ; clear Direction Flag (forward direction, incrementing)
STD ; set Direction Flag (reverse direction, decrementing)
MOVSB, MOVSW, and MOVSD Instructions
All those instruction copy (move) data from memory location pointer to by ESI to memory location pointer to by EDI. Two registers are either incremented or decremented automatically based on the value of DF
Value of incrementation/decrementation is based on the instruction (size of memory)
MOVSB- 1 added/subtractedMOVSW- 2 added/subtractedMOVSD- 4 added/subtracted
Copy Doubleword Array
.data
source DWORD 20 DUP(0FFFFFFFFh)
target DWORD 20 DUP(?)
.code
cld
mov ecx, LENGTHOF source
mov esi, OFFSET source
mov edi, OFFSET target
rep movsd
CMPSB, CMPSW, and CMPSD Instructions
The instructions compare a memory operand pointed to by ESI to a memory operand opinter to by EDI
CMPSB- compare bytesCMPSW- compare wordsCMPSD- compare doublewords
Comparing Doublewords
.data
source DWORD 1234h
target DWORD 5678h
.code
mov ecx, LENGTHOF source
mov esi, OFFSET source
mov edi, OFFSET target
cld
repe cmpsd ; repeat while equal
SCASB, SCASW, and SCASD Instructions
The instructions compare a value in AL/AX/EAX to byte, word, or doubleword respectively, addressed by EDI. They are useful when looking for a single value in a string or array. Combined with REPE or REPZ prefix, the string or array is scanned while
The REPNE prefix scans until either accumulator matches a value in memory or
Scan for a Matching Character
The following code searches for character 'F' in string alpha. If found, EDI points one position beyond the matching character. If not found, JNZ exits
.data
alpha BYTE "ABCDEFGH", 0
.code
mov edi, OFFSET alpha
mov al, 'F'
mov ecx, LENGTHOF alpha
cld
repne scasb
jnz quit
dec edi
STOSB, STOSW, and STOSD Instructions
The instructions store the contents of AL/AX/EAX in memory at the offset pointer to by EDI
LODSB, LODSW, and LODSD Instructions
The instructions load a byte/word/doubleword from memory at ESI into AL/AX/EAX respectively
REP prefix is rarely used because LODS overwrites the accumulator with each new value
Selected String Procedures
This section analizes procedures from Irvine32 library that manipulate null-terminates strings. They are similar to standard C library functions
; copies source string into target
Str_copy PROTO,
source:PTR BYTE,
target:PTR BYTE
; returns length of a string in EAX
Str_length PROTO,
pString:PTR BYTE
; compares string1 to string2, sets ZF and CF in the same way as CMP
Str_compare PROTO,
string1:PTR BYTE,
string2:PTR BYTE
; trims given trailing character from a string
Str_trim PROTO,
pString:PTR BYTE,
char:BYTE
; converts string to uppercase
Str_ucase PROTO,
pString:PTR BYTE
Str_copy Procedure
The Str_copy procedure copies a null-terminated string from a source location to a target location. Before calling, it must be checked that the target operand is large enough to hold the copied string
No values are returned by the procedure
Str_copy USES eax ecx esi edi,
source:PTR BYTE,
target:PTR BYTE
INVOKE Str_length, source ; EAX = length of source
mov ecx, eax ; REP count
inc ecx ; add 1 for null byte
mov esi, source
mov edi, target
cld ; forward direction
rep movsb ; copy the string
ret
Str_copy ENDP
Str_compare Procedure
The Str_compare procedure compares two strings
Compares the strings in forward order, starting at first byte.
Comparision is case sensitive.
Does not return a value, but affects CF and ZF
Flag values
| Relation | Carry Flag | Zero Flag | Branch if True |
|---|---|---|---|
| str1 < str2 | 1 | 0 | JB |
| str1 = str2 | 0 | 1 | JE |
| str1 > str2 | 0 | 0 | JA |
Str_compare PROC uses eax adx esi edi,
string1:PTR BYTE,
string2:PTR BYTE
mov esi, string1
mov edi, string2
L1: mov al, [esi]
mov dl, [edi]
cmp al, 0 ; end of string1?
jne L2 ; no
cmp dl, 0 ; end of string2?
jne L2 ; no
jmp L3 ; yes - exit with ZF = 1
L2: inc esi ; point to next
inc edi
cmp al, dl ; characters equal?
je L1 ; yes - continue loop
; ; no - exit with flags set
L3: ret
Str_compare ENDP
An implementation using CMPSB could also be possible, but would require knowing the length of longer string. Two calls to Str_length would be required, which would make the execution much longer.
Str_length Procedure
Str_length procedure returns the length of a string in the EAX register.
Str_length PROC uses edi,
pString:PTR BYTE
mov edi, pString ; pointer to string
mov eax, 0 ; character count
L1: cmp BYTE PTR [edi], 0 ; end of string?
je L2 ; yes - quit
inc edi ; no - point to next
inc eax ; increment count
jmp L1
L2: ret
Str_length ENDP
Str_trim Procedure
Str_trim removes all occurences of a selected trailing character from a null-terminated string
Logic is interesting because there are number of possible cases
- string is empty
- string contains chars followed by one or more trailing 'Hello##'
- string contains only one charater, the trailing character '#'
- string contains no trailing character 'Hello'
- string contains one or more trailing followed by other '##Hello'
The below implementation tackles only cases 1, 2, 3 and 4
Str_trim PROC USES eax ecx edi,
pString:PTR BYTE, ; points to string
char:BYTE ; character to remote
mov edi, pString
INVOKE Str_length, edi
cmp eax, 0 ; is length equal to zero
je L3 ; yes - exit
mov ecx, eax ; no - ECX = string length
dec eax
add edi, eax ; point to last character
L1: mov al, [edi] ; get the character
cmp al, char ; is it the delimiter?
jne L2 ; no: insert null byte
dec edi ; yes: keep backing up
loop L1 ; until beginning reached
L2: mov BYTE PTR [edi + 1], 0 ; insert a null byte
L3: ret
Str_trim ENDP
Str_ucase Procedure
Str_ucase converts a string to all uppercase characters
Returns no value
Str_ucase PROC USES eax esi,
pString:PTR BYTE
mov esi, pString
L1: mov al, [esi] ; get char
cmp al, 0 ; end of string?
je L3 ; yes: quit
cmp al, 'a' ; below 'a'?
jb L2
cp al, 'z' ; above 'z'?
ja L2
and BYTE PTR [esi], 11011111b ; convert to uppercase
L2: inc esi ; next char
jmp L1
L3: ret
Str_ucase ENDP
Two-Dimensional Arrays
Ordering of Rows and Columns
From an assembly programming perspective, a two-dimensional array is a high-level abstraction of a one-dimensional array. HLL select one of two methods of arranging the rows and columns in memory: row-major order, or column-major order.
When row-major order (most common) is used, first row appears at the beginning of the memory block. The last element of the first row is followed in memory by the first element of the second row.
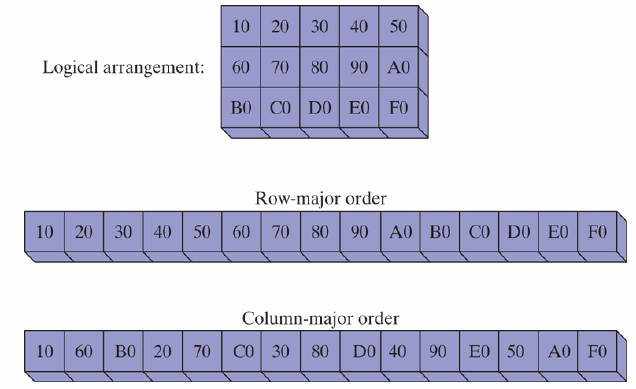
x86 instruction set has two operand types, base-index and base-index-displacement, both suited to array applications
Base-Index Operands
A base-index operand add the values of two registers (base and index) producing an offset address
the square brackets are required
In 320-bit mode, any 32-bit g.p. regs may be used as base and index registers (EBP is avoided except when addressing the stack)
Two-Dimensional Array
When accessing a two-dimensional array in row-major order, the offset is held in the base register and the column offset if in the index register. The following table, for example has three rows and five columns
tableB BYTE 10h, 20h, 30h, 40h, 50h
RowSize = ($ - tableB)
BYTE 60h, 70h, 80h, 90h, 0A0h
BYTE 0B0h, 0C0h, 0D0h, 0E0h, 0F0h
To locate a particular entry in the table using row and column coordinates, the column index can be multiplied by RowSize and added to the row index
row_index = 1
column_index = 2
mov ebx, OFFSET tableB
add ebx, RowSize * row_index
mov esi, column_index
mov al, [ebx + esi]
Scale Factors
If writing code for an array of WORD, the index operand has to by multiplied by scale factor of 2
row_index = 1
column_index - 2
mov ebx, OFFSET tableW
add ebx, RowSizeW * row_index
mov esi, column_index
mov ax, [ebx + esi * TYPE tableW]
Base-Index-Displacement Operands
A base-index-displacement operand combines a displacement, a base register, and an index register, and an optional scale factor to produce an effective address
The formats
displacement can be the name of a variabel or a constant expression. In 32-bit more, any g.p. 32-bit registers may be used for base and index
Base-index-displacement operands are well suited for processing two-dimensional arrays
Displacement can be an array name, base operand can hold row offset, and index operand can hold column offset
mov ebx, RowSize ; row index
mov esi, 2 ; column index
mov eax, tableD[ebx + esi * TYPE tableD]
Searching and Sorting Integer Arrays
Bubble Sort
Compares pairs of array values, beginning at indices 0 and 1
If the values are in reverse order, they are exchanged. This pushes the highest value at the end of the array in one pass. The outer loop starts another pass through the array. After
Pseudocode
cx1 = N - 1
while (cx1 > 0)
{
esi = addr(array)
cx2 = cx1
while (cx2 > 0)
{
if (array[esi] > array[esi + 4])
swap(array[esi], array[esi + 4])
add esi, 4
dec cx2
}
dec cx1
}
cx1 and cx2 are loop counters
BubbleSort PROC USES eax ecx esi,
pArray:PTR DWORD,
count:DWORD
mov ecx, count
dec ecx ; outer loop counter = N - 1
L1: push ecx ; save outer loop counter
mov esi, pArray ; point to first value
L2: mov eax, [esi] ; get array value
cmp [esi + 4], eax ; compare a pair
jg L3 ; if [ESI] <= [ESI + 4], no swap
xchg eax, [esi + 4] ; swap
mov [esi], eax
L3: add esi, 4 ; move to next value
loop L2 ; inner loop
pop ecx ; retrieve outer loop
loop L1
L4: ret
BubbleSort ENDP
Binary Search
One of the most common operations in programming are array searches. For small arrays, a sequential search is easy to do, but for large arrays, it takes a significant amount of time
Binary search is very effective when searching a single item, but requires a precondition - elements must be sorted.
Steps of a binary search :
- Get range of the array with
firstandlastindices - Calculate midpoint of the array between
firstandlast - Compare
xto the integer at midpointmid- If value are equal - return the found value
- If
xis larger, setfirstto one position higher thanmid - If
xis smaller, setlastto one position smaller thanmid
- Return to step 1
This algorithm is extremely efficient, requiring maximum of 32 comparisons for array consisting of
int BinSearch(int arr[], const in x, int count)
{
int first {0};
int last {count - 1};
while (first <= last)
{
int mid {(last + first) / 2};
if (arr[mid] < x)
first = mid + 1;
else if (arr[mid] > x)
last = mid - 1;
else
return mid;
}
return -1;
}
The following is the assembly implementation
BinarySearch PROC USES ebx edx esi edi,
pArray:PTR DWORD, ; pointer to array
count:DWORD, ; array size
x:DWORD ; search value
LOCAL first:DWORD, ; first position
last:DWORD, ; last position
mid:DWORD ; midpoint
mov first, 0 ; first = 0
mov eax, count
dec eax ; last = count - 1
mov last, eax
mov edi, x ; EDI = x
mov ebx, pArray ; EBX points to array
L1: mov eax, first
cmp eax, last ; first <= last (impossible to search)
jg L4 ; exit search
mov eax, last
add eax, first
shr eax, 1
mov mid, eax ; mid = (first + last) / 2
mov esi, mid
shl esi, 2
mov edx, [ebx + esi] ; EDX = arr[mid]
cmp edx, edi
jge L2 ; if EDX < x
mov eax, mid
inc eax
mov first, eax ; first = mid + 1
jmp L1 ; continue the loop
L2: cmp ecx, edi ; else if EDX > x
jle L3
mov eax, mid
dec eax
mov last, eax ; last = mid - 1
jmp L1 ; continue the loop
L3: mov eax, mid ; value found
jmp L9
L4: mov eax, -1 ; search failed
L9: ret
BinarySearch ENDP