7 - Hypothesis Testing
Hypothesis Testing
Introduction
Definitions
Hypothesis - a claim about reality
Competing Hypothesis - a pair of opposing hypotheses regarding a particular aspect, such that one of them must be true
Null Hypothesis
Alternative Hypothesis
- Poses the greater negative impact if acting as if it is true when it is indeed false
- In scientific inquiry, it is typically the desired result
Hypotheses Testing - Process of collecting and weighing evidence againstto determine if there is enough evidence to reject as true
Conclusions
If there is enough evidence against the
We reject the null hypothesis in favour of the alternative one
This does NOT prove
There is sufficient evidence to begin acting in accord with the alternative hypothesis
If there is not enough evidence against the
We fail to reject the null hypothesis
This does NOT prove
There is not a strong enough reaso to alter our default position in determining how to act away from
Practical judgment is necessary when determining how to act in accord with a hypothesis and the evidence
Consequences of Hypothesis Testing and Assessing Evidence
Errors
Type I Error - Rejecting a true null hypothesis
Type II Error - Failing to reject a false null hypothesis
Determining Sufficient Evidence
Given a true null hypothesis
- how ofter are we okay making a type I error?
- for what proportions of samples are we okay rejecting the truth because the statistics produced are rare enough?
Assessing Evidence
The p-value is the probability of obtaining evidence at least as rare as the evidence collected under the assumption that the null hypothesis is true
If the p-value is very small, it indicates that something rare or unusual happened in the case that the null hypothesis is true
If the p-value is not very small, it indicates that something routine or usual happened in the case that the null hypothesis is true
If the p-value is small enough, it makes us question whether assuming the null hypothesis is true is the right way to act
For single-tail tests, there are infinitely many parameter values in the null hypothesis. The border value is chosen for the calculation as it provides the worst-case probability value
Determining Sufficiency of Evidence
We set the standard for sufficient evidence by determining which p-values are small enough to reject the null hypothesis
If the p-value is less than the value we set, we reject the null hypothesis
We call this value the
- p-value
- reject the null hypothesis - p-value
- fail to reject the null hypothesis
It is possible that the collected evidence is rare enough to result in p-value underdespide null hypothesis being true
The significance level is the probability of making a type I error given that the null hypothesis is true
Hypothesis Testing Procesure
- Identify competing hypotheses
- Set significance level
- Determine sample size
p-value distribution is a probability calculating from the sampling distribution. Select sample size large enough so that the shape of the sampling distribution can be approximated - Select a sample via SRS
- Collect and study the sample. Compute sample statistics
- Compute the p-value and make statistical conclusion
p-value- reject in favor of
p-value- fail to reject - In light of statistics conclusion, determine if a change in behaviour is prudent and practical
Claims on Means
Each member of the population has a numerical value associated with it. We are interested in the average of these values
Need
Need a SRS
Computing the p-value
The sample statistic that we compute from our collected sample is our evidence. The value reisdes along the horizontal axis of the sampling distribution
p-value is computed by computing probability that at least as extreme as our test statistic is achieved under the assumption that the null hypothesis is true in the worst case scenario (equal to border value)
If we know the standard deviation of the sampling distribution, we can calculate the p-value easily
If we do not know the standard deviation of the sampling distribution, we must transform our problem
Many people like to transform the problem regardless of whether we know the standard deviation of the sampling distribution
The sampling distribution is approximately normal
If
which resides in the t-distribution
Excercises
Hypothesis Test
A software designer is testing the efficiency of the new version of program. He hopes that new version is faster than the last one. Both versions are run 14 times (different computers, same set of websites). Test developer's claim at the 0.01 level of significance assuming that the differences come from a normal distribution.
| Old | New |
|---|---|
| 12.4 | 10.2 |
| 13 | 7.8 |
| 14.5 | 9.3 |
| 13.2 | 14 |
| 10 | 7 |
| 16 | 16 |
| 14.3 | 16.6 |
| 9.3 | 5.6 |
| 14.2 | 15.7 |
| 9.3 | 7.1 |
| 11.5 | 7.8 |
| 13.6 | 6.1 |
| 9.2 | 4 |
| 12.4 | 13.2 |
For the program to be faster:
We calculate all differences as:
approx, random, norm
t-test
this
We put
p-value:
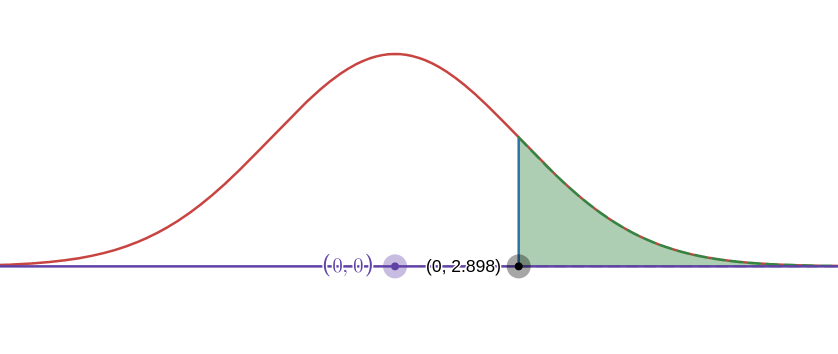
green area is the p-value, which is the area for which
The area on the left of
Claims on Proportions
We are interested in the percentage of members with a particular quality
We need
Exercises
Harper's Index reported that 80% of all supermarket prices and in the digits of 9 or 5. From your recollection, this estimate seems too high. You randomly select 115 items from supermarket price catalogs and find that 88 have prices that end with a 9 or 5. Test the claim at the 1% level of significance.
random
88% have 5 or 9 at the end, so
Doing distribution:
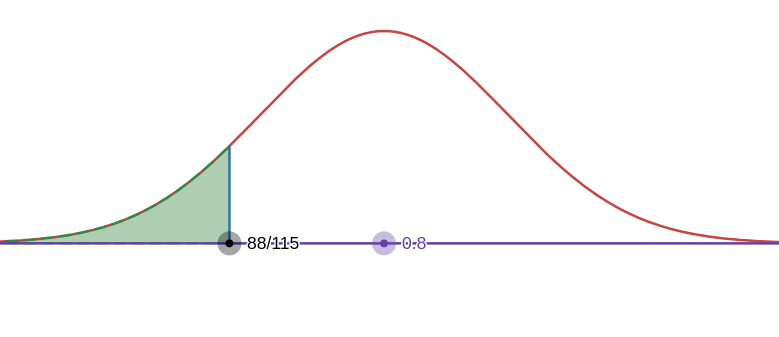
p-value is bigger than our
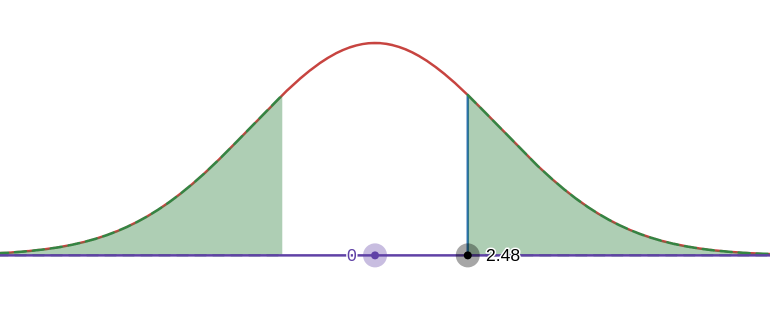
Myers-Briggs estimates that about 82% of college student government leaders are extroverted. A random sample of 73 student government leaders were given the Myers-Briggs personality test; 68 of them were found to be extroverted. Test the claim that the actual percentage is different that what was reported at a significance level of 2%
it is random
Doing test statistic:
According to the Pew Research Center, the average number of FB friends is 338. A random sample of 100 users had an average of 287 friends with a standard deviation of 50 friends. Test the claim that the average number of friends is less than reported by Pew using a significance level of your choosing.
A delivery service claims to deliver packages from NYC to LA in 24 hours on average. It is well-agreed upon the delivery services have a standard deviation of 2 hours. Several complaints about this particular service have been made about delivery taking longer than advertised. An independent consumer agency conducted a study. A random sample of 35 packages produces a mean of 24.85 hours. Test the claim at